论文阅读 - 《Large Language Models Are Zero-Shot Time Series Forecasters》
本文最后更新于:2024年3月9日 中午
Abstract
通过将时间序列编码为数字组成的字符串,我们可以将时间序列预测当做文本中下一个 token预测的框架。通过开发这种方法,我们发现像GPT-3和LLaMA-2这样的大语言模型在下游任务上可以有零样本时间序列外推能力上持平或者超过专门设计的时间序列训练模型。为了促进这种性能表现,我们提出了一种有效token化时间序列并将token上的离散分布转换为在连续数值上高度灵活的密度的方法。我们认为大语言模型在时间序列上的成功源于它们可以自然的表达多模态分布的能力,以及为了简单而出现的偏差和重复,这与许多时间序列中的显著特征类似,例如重复的季节趋势。我们同样展示了大预言模型如何做到在不通过非数字文本进行插补的情况下自然的处理缺失的数据,适应文本的便捷信息,并且回答问题以帮助解释预测。同时我们发现日益增大的模型体积有助于改进其在时间序列上的性能表现,我们也展示了GPT4由于其不同对数字的token化方式以及较差的不确定性校准而表现要比GPT3要差,这可能是类似于RLHF这样的对齐机制干预的结果。
提出的方法
Tokenization
将每个数字用空格分开,并在每个时间节点之间用,分隔,小数点在给定固定精度情况是多余的,可以使用特定的编码方式去掉小数点以节省上下文长度。例如:
$$
0.123, 1.23, 12.3, 123.0 \rightarrow 1 2 , 1 2 3 , 1 2 3 0 , 1 2 3 0 0
$$
Rescaling
因为数值有可能非常大,要覆盖那么多数值需要很多的token。因此,在输入之前,会用MinMaxScaler将数值进行缩放,限制数值的范围。
Sampling/Forecasting
在每次预测时,都会多次实验采样多组预测值,将多组预测值的中位数或均值作为点预测结果,使得结果更加鲁棒,而且还可以直接作为概率预测的结果(分位数)。
Continuous likelihoods
虽然LLM的概率分布是离散的(即token是离散的),但是可以将其转换为连续概率密度。
如下图所示的例子,假如保留三位小数,则每0.001范围形成一个bin,bin内的所有数值服从均匀分布。如0.537和0.538之间的这个bin内,赋一个均匀分布。这样,LLM的概率分布就成了连续的。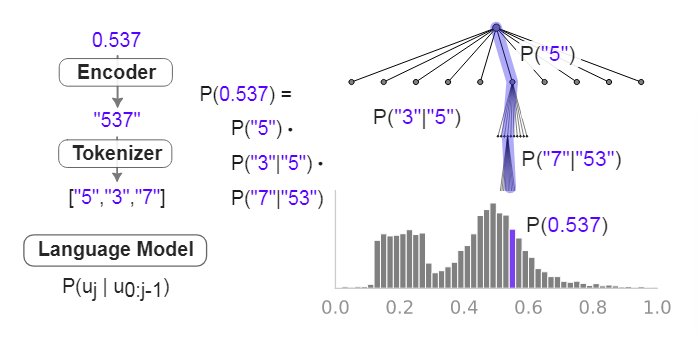
首先,假设我们有一个语言模型,它可以生成数字序列,比如小数点后的一串数字。这些数字的概率分布是离散的,因为每个数字都有一个特定的概率。
为了将这个离散的概率分布变成连续的,作者采用了一种巧妙的方法。他们把可能的数字值按照一定的规则划分成许多小区间,每个区间都是一个连续的范围。然后,在每个区间内,假设数字的分布是均匀的,也就是说,每个具体的数字在这个区间内出现的概率是一样的。
通过这样的构建,整个数字空间被分割成许多这样的区间,每个区间都有一个概率分布。这种方法允许我们将原本离散的数字概率分布转换成一个连续的概率分布。
最后,为了在原始输入空间中得到这个连续的概率分布,作者引入了一个变量变换的操作。这个操作确保了我们在处理数据时,可以从离散的数字空间映射到连续的数字空间。
总的来说,通过这种方法,尽管我们的模型输出的是离散的数字,但我们可以用一种更灵活、更高分辨率的方式来表示和处理连续的概率分布。
Language models as flexible distributions
Wasserstein距离,也称为地面距离或水流距离,是一种用于衡量两个概率分布之间差异的数学指标。在这个上下文中,作者使用Wasserstein距离来评估通过训练模型生成的连续概率分布与真实分布之间的相似程度。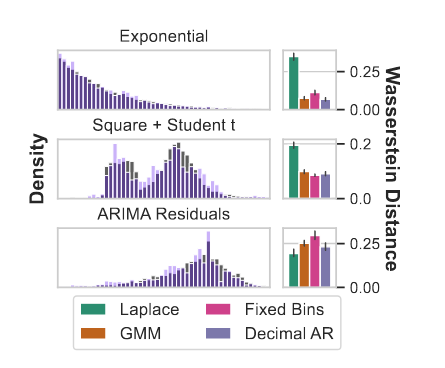
具体来说,作者首先在上图所示的各种一维分布上训练了一个小型自回归模型。这些分布包括指数随机变量、均匀分布、学生t分布的混合分布,以及月度牛奶数据集上ARIMA模型的时间序列预测残差的重尾分布。接着,作者计算了生成的概率分布与真实分布之间的Wasserstein距离。
Wasserstein距离的计算涉及到将一种分布转换为另一种分布的最佳办法,使得转换的成本最小。在这个上下文中,它衡量了通过模型生成的分布与真实分布之间的“距离”或差异,这个距离值越小,两个分布之间的相似性就越高。
通过比较不同模型的Wasserstein距离,作者可以评估模型在处理不同类型的分布(非对称、多模态和重尾分布)时的性能。在这里,十进制自回归语言模型(”十进制 AR”)表现出色,表明它在生成与时间序列数据特征相匹配的概率分布时效果良好。这种评估方法提供了一种量化模型性能的手段,特别是在处理复杂概率分布时。
Origins of Zero-Shot Performance
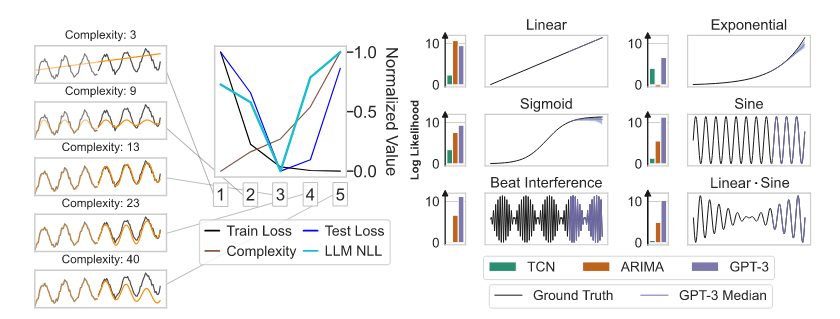
假如有一个人工生成的序列,用不同复杂度的模型来拟合它(比如不同次数的多项式函数),然后外推,我们希望找到较小复杂度的模型,既能拟合很好,又不会过拟合,如下图中的复杂度13。这叫奥卡姆剃刀原理。可以发现,LLM的NLL最小的时候,正好对应的是这个复杂度13的模型。也就是说,LLM可以找到数据的低复杂性解释,使他们能够zero-shot外推数值序列。
- Rpetition bias and periodicity:LLM对于重复序列的偏差恰好对应于识别和推断输入中周期结构的能力。
- Arithmetic and trend components:LLM有对于加法和乘法的执行能力
将多个模式组合在一起是一个更困难的挑战,因为它需要识别复合模式并能够在相同的令牌预算内执行多个操作。假设一个模型可以在一次正向过程中执行复制,在一次反向过程中执行加法,这并不一定意味着它可以同时执行这两项操作。我们发现,尽管GPT-4的执行更一致,GPT-3却能执行这些合成(而这是GPT-4所不能的),如附录E所示。对计算和令牌的限制可能会使这种合成变得不必要地困难,而额外的递归结构,例如来自草稿簿、思想链(CoT)提示或自适应计算,会使这项任务更容易。
LLM其它特性分析
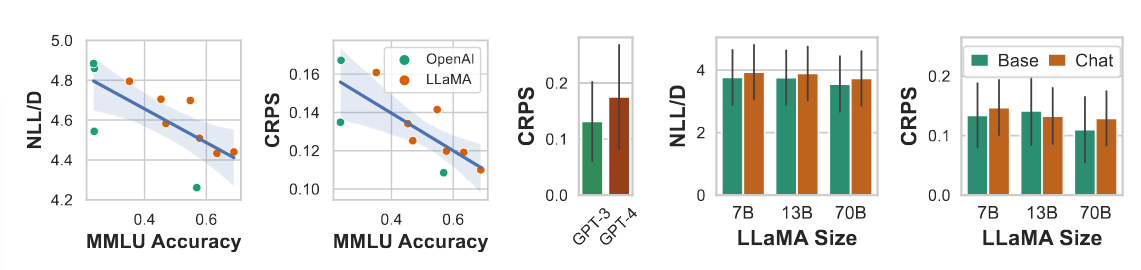
Base models and forecasting performance
如图所示,本文使用OpenAI模型、LLaMA及LLaMA-2模型测量大规模多任务语言理解基准和概率预测误差准确性的研究,展现了当推理性能提高时,预测能力也会提高。
Chat Models
尽管方便的缩放关系似乎适用于基本模型,但当我们考虑已经为聊天机器人应用程序进行后处理的模型时,这种关系开始破裂。例如,GPT-4在自然语言任务中表现出比GPT-3和LLaMA模型高得多的智能,但将其有效应用于时间序列却变得更加困难。在上图(中间部分)中,展示了GPT-4的预测误差(CRPS)明显大于Darts数据集上的GPT-3。性能下降是GPT-4方法中几个小细节的结果。由于标记化的改变,GPT-4不能轻易地被迫将单个数字标记成一个完整的数字流。由于API的限制,可能性评估也是不允许的,这就是为什么我们只提供CRPS的结果。虽然GPT-4可以在第5节(如附录E所示)中讨论的合成示例中表现良好,但我们发现,在随机数据中,GPT-4的校准比GPT-3的差得多,这可能是由于上述预处理细节以及使用RLHF处理模型的事实,众所周知,RLHF会降低问答任务的校准。GPT-4并不是为聊天功能设计的模型中性能下降的唯一例子。我们在LLaMA-2模型中观察到了同样的现象,它们对每个模型大小都有相应的聊天版本。图7(右)显示,聊天版本的预测误差往往比非聊天版本明显更差,尽管在规模和推理能力方面仍保持趋势。
Missing data
在实际的时序预测场景中,经常会有缺失值NaNs出现。传统方法是直接插值补齐这些缺失值,但是直接插值显然可能和真实值有些差距。而LLM则无需补齐,直接把NaN这个单词给放到序列句子中就好,比如:
上面式子中逗号之间没有值的都是缺失值,无需插值,直接插入NaN即可。
下图是预测效果,发现对于缺失数据非常多的情况,LLM仍然能够有着很低的负对数似然值,而插值+预测模型这种方式的负对数似然都飘到天上去了。在CRPS这个预测指标上看,LLM的预测效果也是不错的。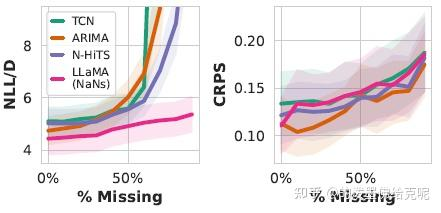
Connecting time series and textual understanding
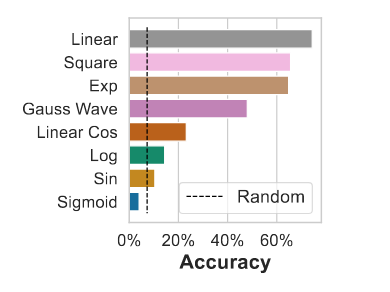
由于 LLM 是为自然语言和代码而设计的,因此我们可以用有用的文本来增强数值时间序列。我们可以通过提供文本侧信息作为输入,或者通过给定的时间序列产生文本输出来实现这一点。一个有趣的问题是,GPT-4 能否用文本解释其对给定时间序列的理解。我们为 GPT-4 提供了生成合成时间序列的代码,提供了其中一个时间序列的值,然后要求它推断出是哪个函数以零点方式生成了数据,以此来探究 GPT-4 的这一能力。预测准确率如上图所示,其余三行均为 0。在 CoT的提示下,模型的表现比随机概率要好得多;不过,在直接推断数字数据时,它识别模式的能力更强,这表明它对数字的理解与其对文本的理解并不完全相关。在进行预测时,模型经常会解释时间序列的属性,以便从列表中选出正确的候选结果,我们在附录 F 中展示了其中几个解释示例。我们还展示了如何在 Jupyter 笔记本单元格上的一个简单(无提示)的下一个标记预测问题中封装这一任务,说明了为什么我们期望这种能力会随着一个足够强大的语言模型的出现而出现。
Summary
我们已经证明,通过将数值编码为文本,大型语言模型可以用作预训练时间序列预测器。与其他 “基础 “模型一样,预训练会使模型具有有用的通用模式偏差,而这些偏差会通过架构设计,并随着基础预训练模型的改进而实现性能的自然扩展。由于 LLM 预测器是在语言基础上进行训练的,因此还具有非常规能力,如问题解答。从更广泛的意义上讲,将时间序列预测视为自然语言生成,可以说是将更多能力统一到一个大型、功能强大的模型中的又一举措,在这个模型中,许多任务和模式之间可以共享理解能力。此外,零点预测不需要大量的计算资源、领域专业知识或许多下游训练数据点,就能实现令人信服的广泛性能。
虽然 LLM 预测器得益于预训练转换器的优势,但也继承了它们的弱点,其中包括有限的上下文窗口。虽然许多单变量时间序列问题可以在越来越大的上下文窗口内轻松解决,但多变量问题却带来了更大的挑战。最近有几项进展将 LLM 的上下文窗口扩展到了 10-100K 字节。将这些进展与时间序列预测相结合是未来研究的一个特别令人兴奋的方向。使用当前 LLMs 架构的另一个潜在挑战可能是它们在算术和执行递归与组合操作方面的弱点,这可能会限制特别具有挑战性的时间序列。另一方面,许多时间序列并不需要精确的运算。了解这种情况在多大程度上存在,并放宽这种限制,也是未来研究的一个很有前景的方向。除了任何限制之外,研究微调时间序列 LLM 的有效程序也很有前途。我们希望将 LLM 研究与时间序列预测结合起来,为两个领域都带来益处。