DeepLabv3+语义分割实例记录-路坑标注
本文最后更新于:2023年11月8日 中午
本文默认
- 已经装配好了anaconda
- 拥有NVDIA支持进行GPU运算的显卡以及正确装配的驱动
- 已配置好了代理以及下载加速
- 操作环境为Windows 11+Kali Linux(WSL2)
环境配置
基础环境
首先创建一个anaconda的虚拟环境,进入Anconda Prompt,这里我就用pytorch作为环境名,python3.8为必须选项(网上大部分描写的3.6版本python现在已经不受支持,使用最新环境中会遇到诸多问题)
1 | |
安装成功后激活环境
1 | |
如果前面显示(pytorch),则说明已经成功进入环境,然后执行pytorch安装命令(最新命令可以在官网查到)
1 | |
Deeplabv3+装配
克隆和安装deeplabv3+
1 | |
clone成功后在其目录下执行
1 | |
装配相关依赖
数据集收集
这里使用经典的VOC2007以及VOC2012数据集进行处理,下载之后得到几个数据集文件在本地进行解压。
文件夹层次为VOCdevkit/VOC2007和VOCdevkit/VOC2012
VOC2007和VOC2012下面有若干分类后的文件夹
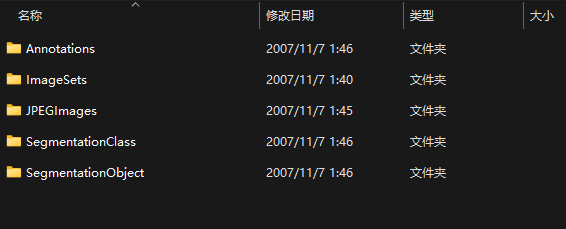
- JPEGIamges放所有的数据集图片
- Annotations放所有的xml标记文件
- SegmentationClass放标注的数据集掩码文件
- ImageSets/Segmentation下存放训练集、验证集、测试集划分文件
- train.txt给出了训练集图片文件列表(不含后缀)
- val.txt给出了验证集图片文件的列表
- trainval.txt给出了训练集和验证集图片文件的列表
- test.txt给出测试集图片文件的列表
权重文件放置
在主目录下新建weights文件夹,将.pth标识的权重文件放入
测试图片
使用deeplabv3plus_mobilenet模型
1 | |
标注工具-LabelMe安装
安装使用
进入Anaconda,新建一个python版本为3.6的虚拟环境,然后进入该环境,使用pip进行安装
1 | |
接着在该环境执行命令
1 | |

打开软件,进行标注,标注后生成json文件,最后将数据集图像文件以及标注的json文件放置在~/mydataset目录下
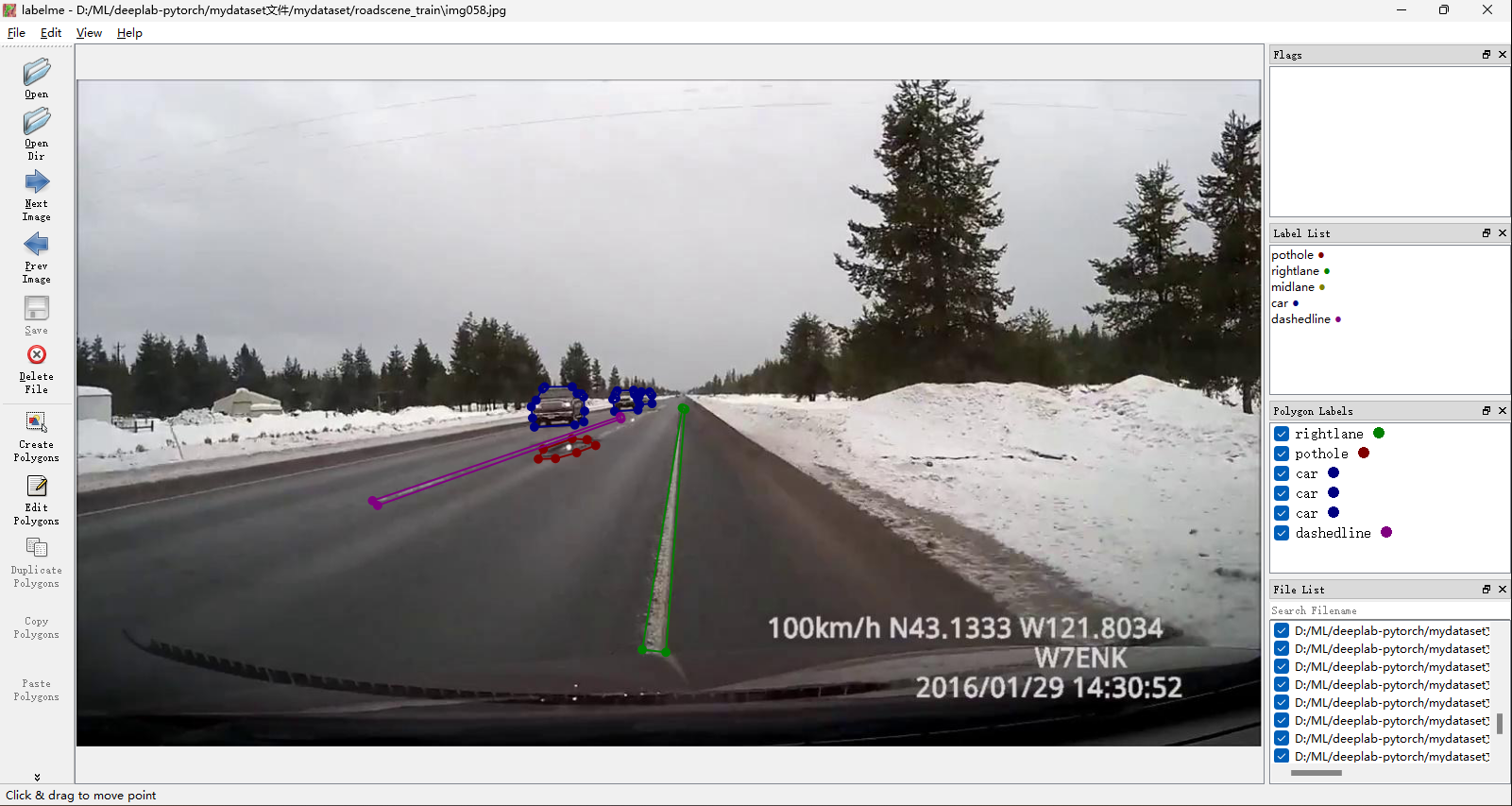
数据转换
1 | |
模型训练
训练网络
使用deeplabv3plus_mobilenet模型
1 | |
--model: 指定使用的模型--enable_vis: 启用visdom可视化--vis_port: 指定visdom使用的端口--gpu_id: 指定gpu的id--year: 指定训练数据--crop_val: 声明进行crop操作--lr: 声明learning rate(学习率)--crop_size: 指定crop之后的图片格式为513x513-- batch_size: 声明batch size--output_stride: 网络模型对图片进行指定倍数的下采样--num_classes: 设定为类别数+1--total_itrs: 迭代数目--ckpt: 预训练权重文件
验证网络模型
整体测试集
1 | |
最后结果保存在result文件夹下
图片测试
单张图片测试
1 | |
多张图片测试
如果是jpg图片,修改predict.py中
1 | |
为
1 | |
然后再执行命令即可
结果展示



DeepLabv3+语义分割实例记录-路坑标注
https://www.0error.net/2022/04/d2c1a00.html